
线程
在早期的操作系统中都是以进程作为独立运行的基本单位,直到后面,计算机科学家们又提出了更小的能独立运行的基本单位,也就是线程。
为什么使用线程
进程之前不好通信、共享数据
维护进程的系统开销大
故提出了一个新的实体:线程,线程之间可以并发运行且共享相同的地址空间
什么是线程
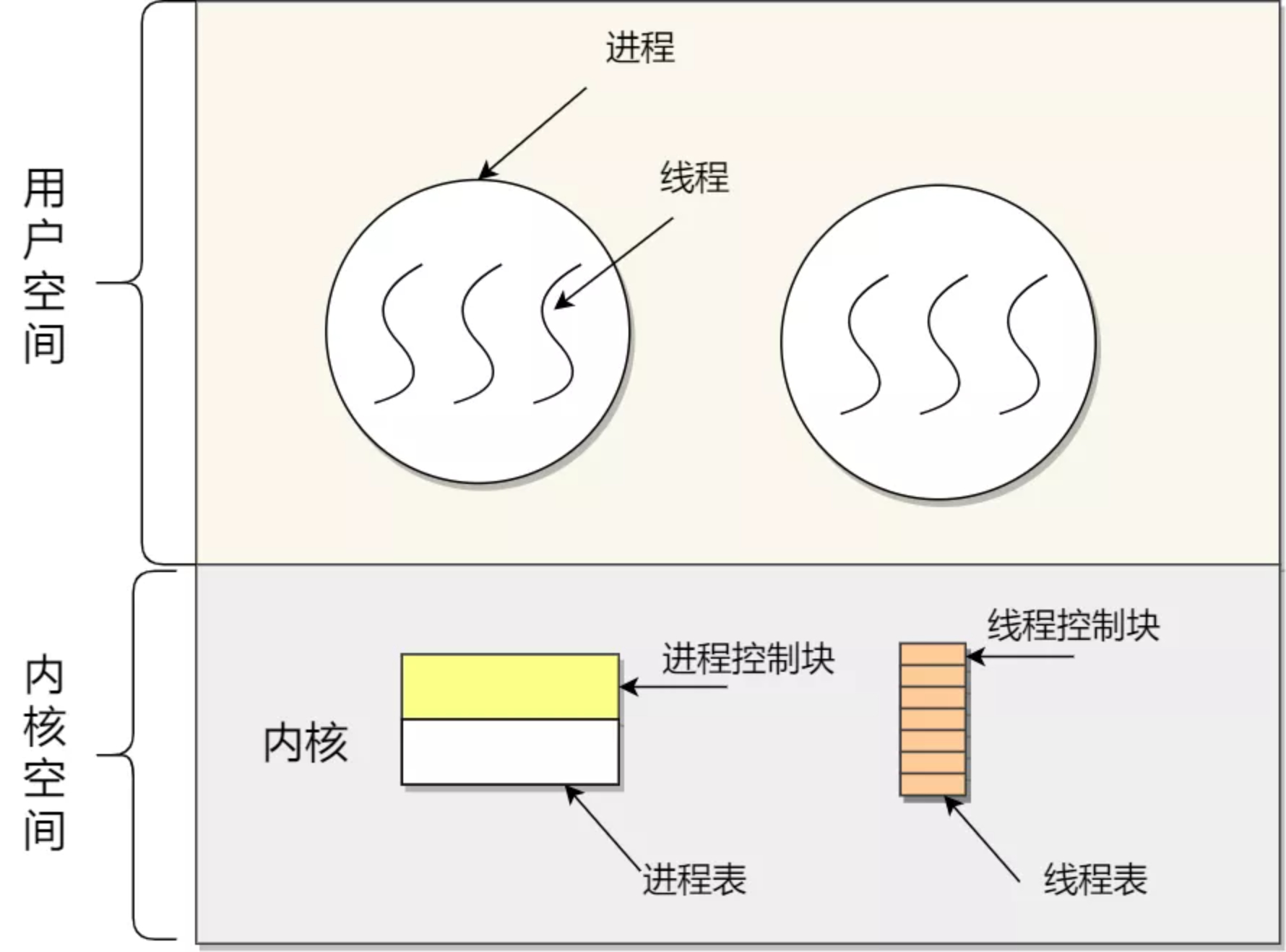
线程是进程当中的一条执行流程。
同一个进程内多个线程可以共享代码段、数据段、打开的文件等资源,但每个线程又有独立的一套寄存器和栈,来保证线程的控制流程是相对独立的。
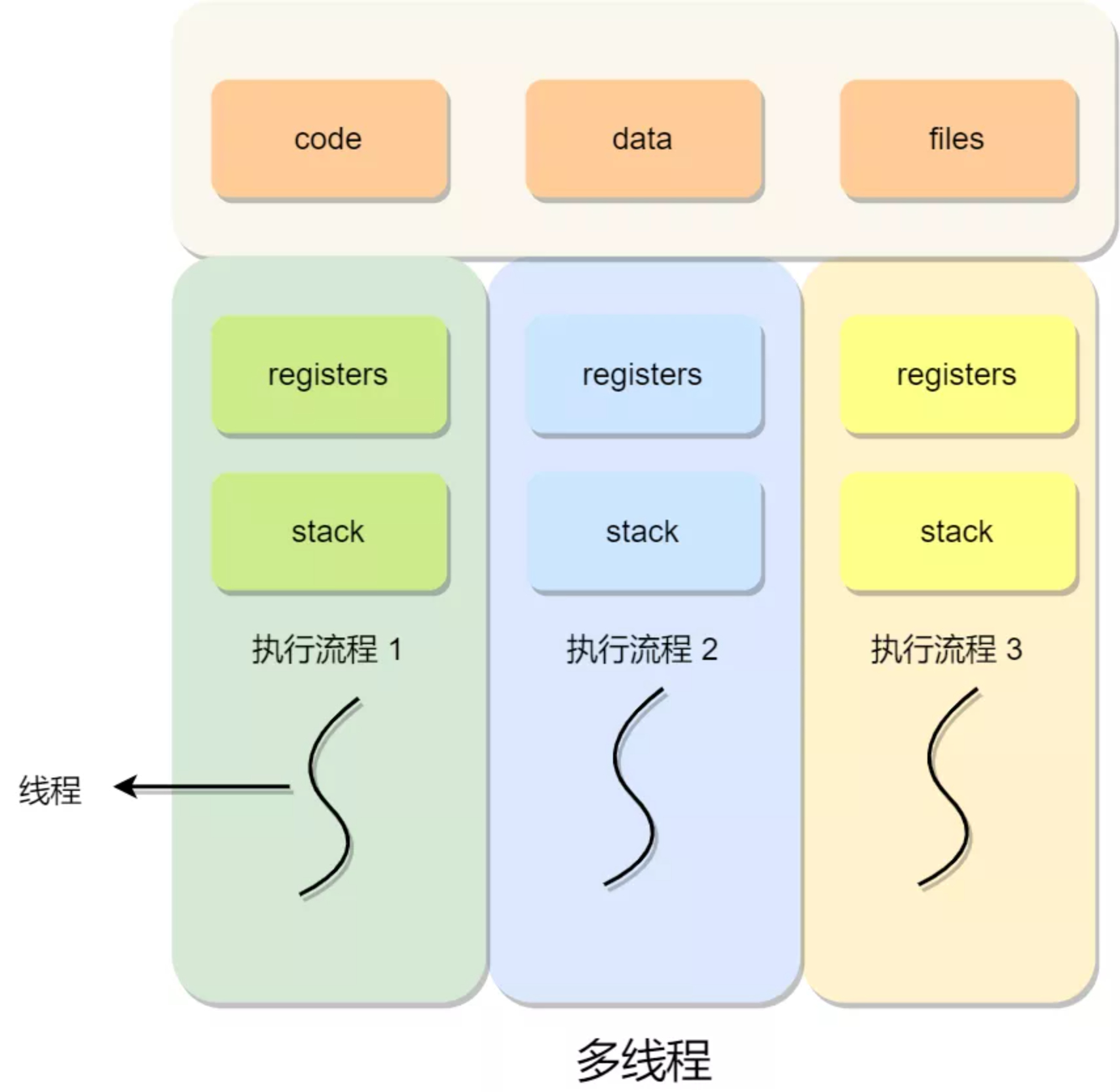
线程的优缺点
优点:
一个进程中可以同时存在多个线程
各个线程可以并发执行
各个线程之间可以共享地址空间和文件等资源
缺点:
当进程中一个线程崩溃是,会导致其所属进程的所有线程崩溃
线程与进程的比较
进程是资源(内存、打开的文件等)分配的单位,线程是 CPU 调度的单位
进程拥有一个完整的资源平台,而线程只独享必不可少的资源,如寄存器和栈
线程同游具有就绪、阻塞、执行三种基本状态,同样具有状态之间的转换关系
线程能减少并发执行的时间和空间开销
线程如何减少开销
线程的创建时间比进程快:因为进程在创建的过程中,还需要资源管理信息(比如内存管理信息、文件管理信息),而线程在创建过程中,不会涉及这些资源管理信息,而是贡献它们
线程终止的时间比进程快:因为线程释放的资源比进程少
同一个进程内的线程切换比进程切换快:因为线程具有相同的地址空间(虚拟内存共享),这意味着同一个进程的线程都具有同一个页表,那么在切换的时候不需要切换页表。而对于进程之间的切换,切换的时候要把页表切换掉,而页表的切换比较大
同一个进程的各线程间共享内存和文件资源:在线程之间数据传递时,就不需要经过内核了,线程间数据交互效率更高
所以无论时间还是空间,线程的效率都更高。
线程上下文切换
线程与进程最大的区别:线程是调度的基本单位,而进程则是资源拥有的基本单位。
所以操作系统的任务调度,实际上调度的对象是线程,而进程只是给线程提供了虚拟内存、全局变量等资源。
当进程只有一个线程时,可以认为进程就等于线程
当进程拥有多个线程是,这些线程会共享相同的虚拟内存和全局变量等资源,这些资源在上下文切换时时不需要改变的
另外,线程拥有自己的私有数据,比如栈和寄存器等,这些在上下文切换时时需要保持的。
所以对于线程的上下文切换,要看线程是不是属于同一个进程:
当两个线程不属于同一个进程,则切换的过程就和进程上下文切换一样
当两个线程属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源是不变的,只需切换线程的私有数据、寄存器等不共享的数据
由此也可看出,线程的上下文切换比进程的开销要小的多。
线程的实现
线程主要有三种实现方式:
用户线程(User Thread):在用户空间实现的线程,不受内核管理,是由用户态的线程库在完成线程的管理
内核线程(Kernel Thread):在内核中实现的线程,是由内核管理的线程
轻量级进程(LightWeight Process):在内核中来支持用户线程
用户线程和内核线程的对应关系:
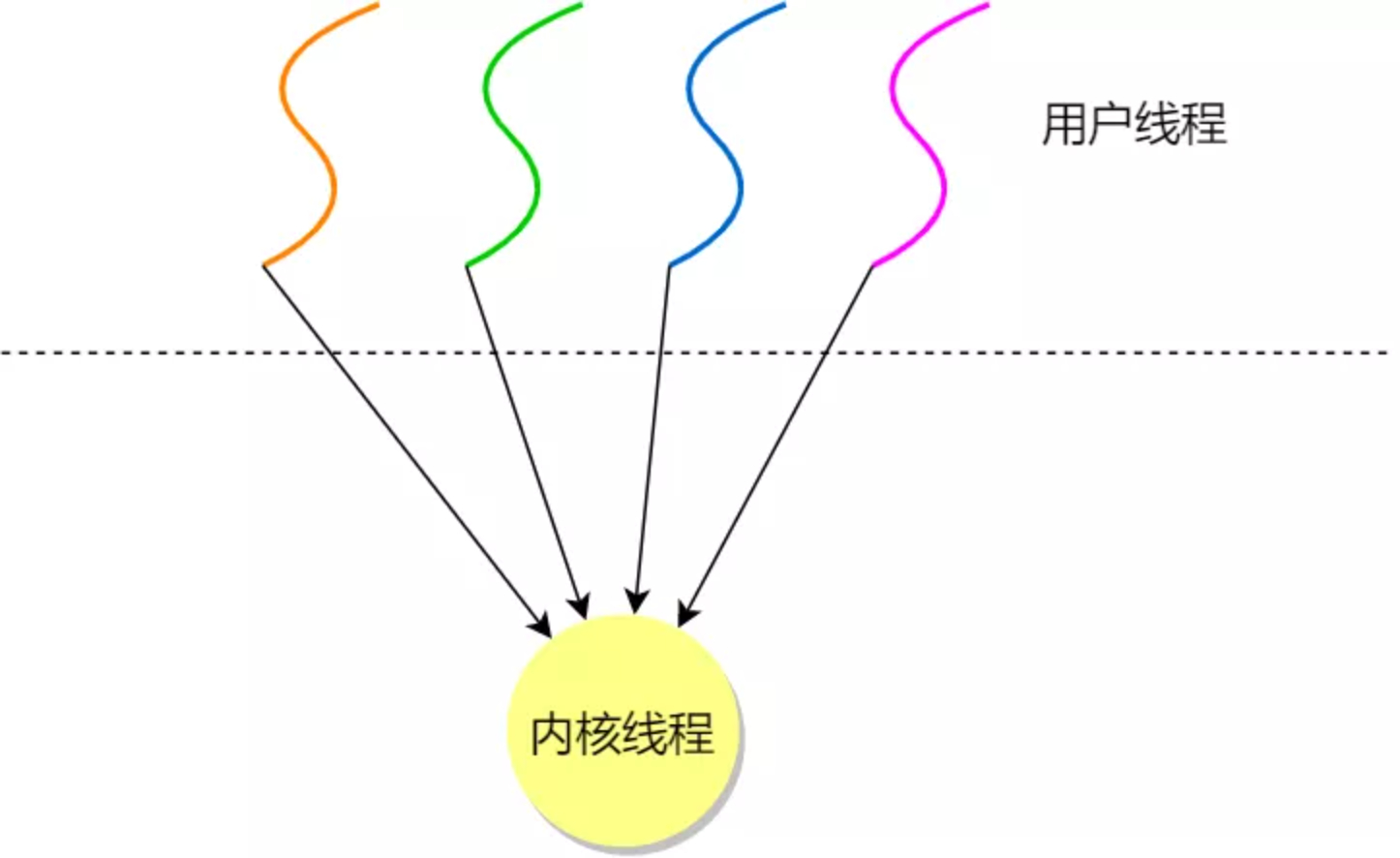
多对一:多个用户线程对应一个内核线程。
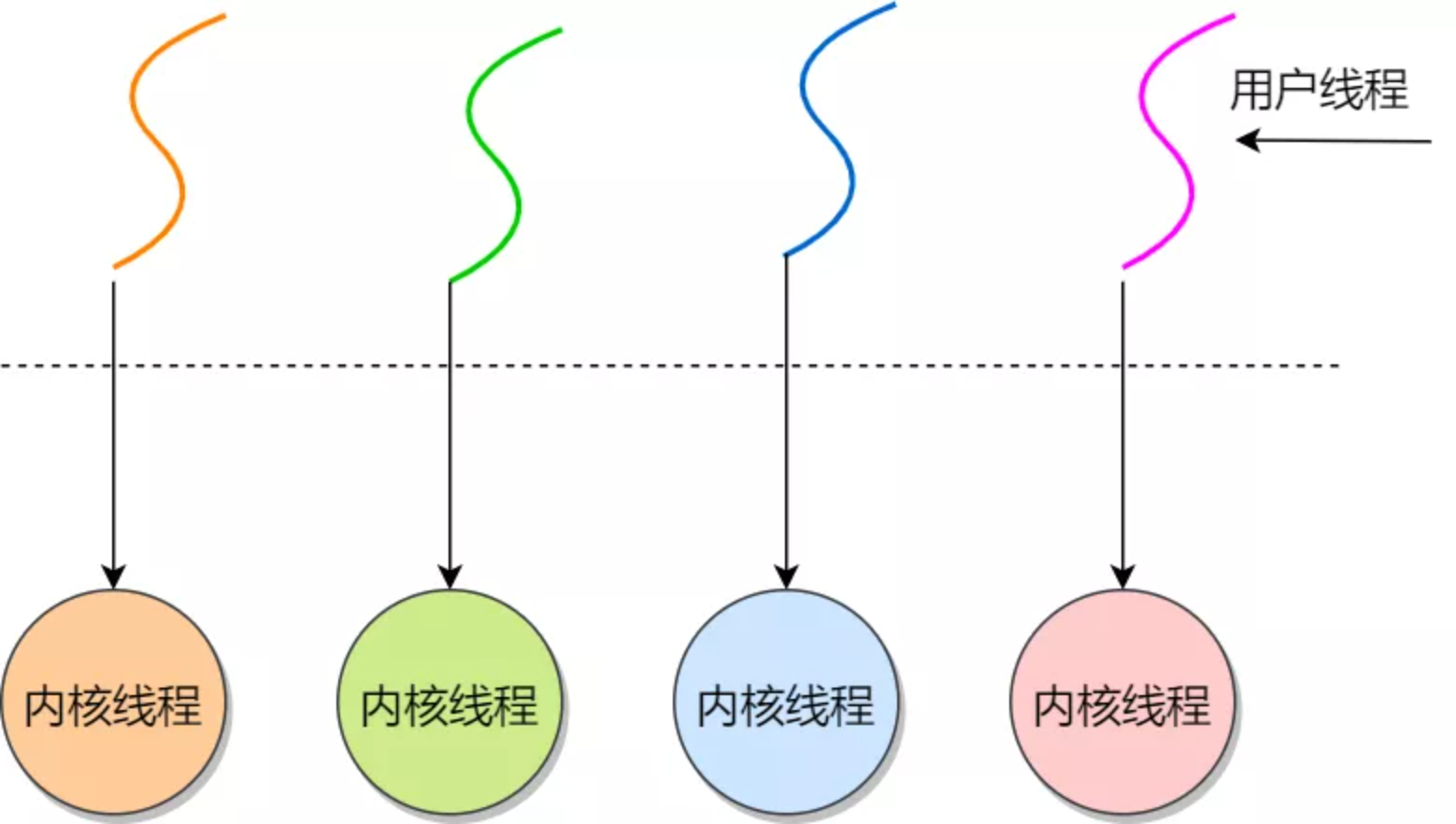
一对一:一个用户线程对应一个内核线程。
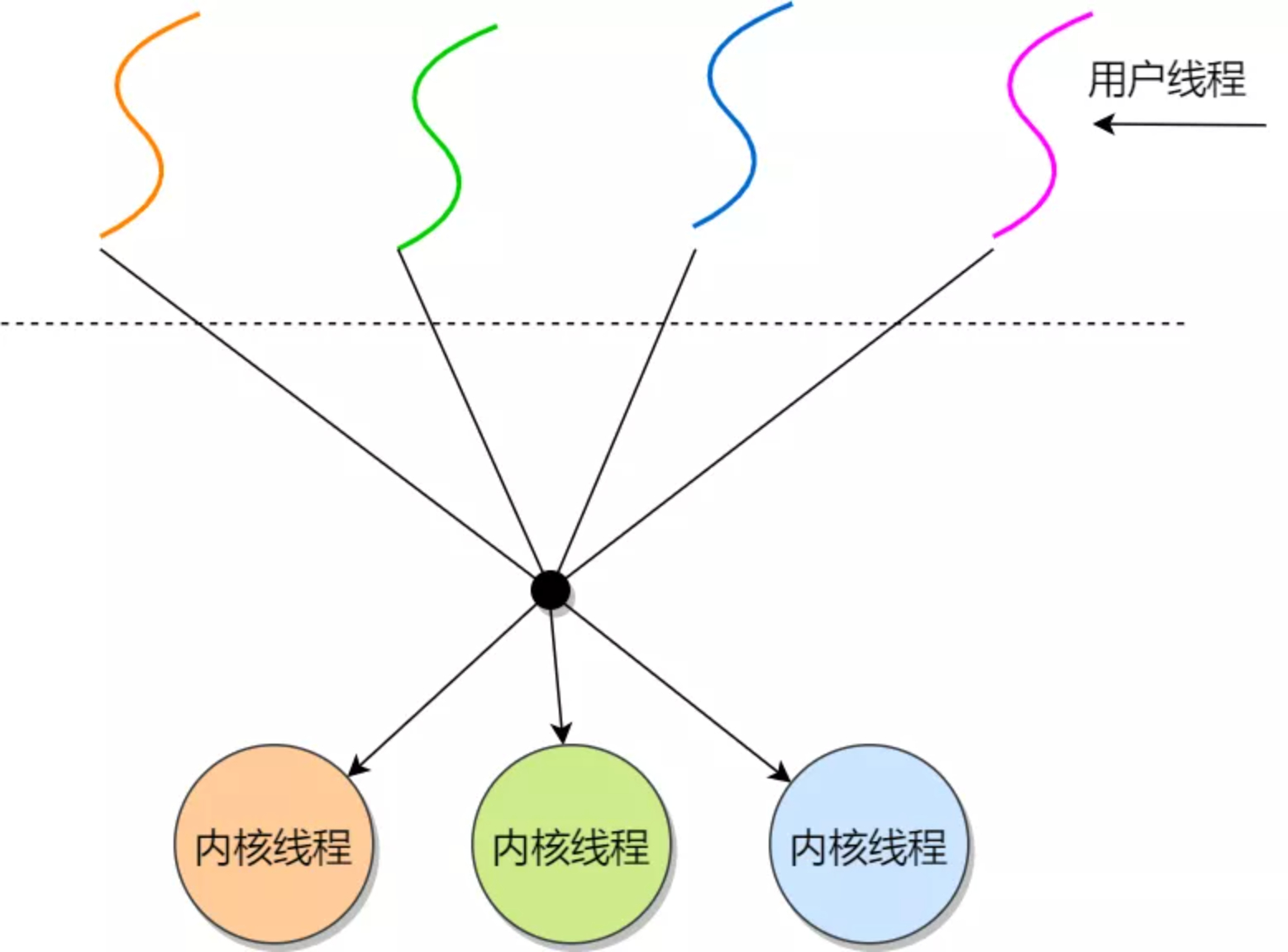
多对多:多个用户线程对应多个内核线程。
用户线程
用户线程是基于用户态的线程管理库开实现的,线程管理快(Thread Control Block,TCB)也是在库里面实现的,对于操作系统而言是看不到 TCB 的,只能看到 PCB。
用户线程的整个线程管理和调度,操作系统是不直接参与的,而是用用户线程库函数来完成线程的管理,包括线程的创建、终止和调度。
用户线程模型,类似于多对一的关系,即多个用户线程对应同一个内核线程。
优点:
可用于不支持线程技术的操作系统:TCB 由用户级现场库来维护,每个进程都需要有它私有的进程控制块(TCB)列表,用来跟着记录它各个线程的状态信息(PC、栈指针、寄存器)
用户线程的切换有线程库完成,无需用户态与内核态的切换,所以速度非常快
缺点:
由于操作系统不参与线程的调度,如果一个线程发起了系统调用而阻塞,那么进程所包含的用户线程就都不能执行了
当一个线程开始运行后触发它主动交出 CPU 的使用权,否则它所在的进程当中的其他线程无法运行,因为用户态的线程没法打断当前运行中的线程,它没有这个特权,只有操作系统才有,但是用户线程不是由操作系统管理的
由于时间片分配给进程,故与其他进程比,在多线程执行时,每个线程得到的时间片较少,执行会比较慢
内核线程
内核线程是由操作系统管理的,线程对应的 TCB 是放在操作系统里的,这样线程的创建、终止和管理都是有操作系统来负载。
内核线程模型,类似于一对一的关系,即一个用户线程对应一个内核线程。
优点:
在一个进程中,如果某个内核线程发起系统调用而被阻塞,并不会影响其他内核线程的运行
分配给多线程的进程更多的 CPU 运行时间
缺点:
由内核来维护进程和线程的上下文信息,如 PCB 和 TCB
线程的创建、终止和切换都是通过系统调用的方式来进行,对于系统开销较大
轻量级进程
轻量级进程(Light-weight process,LWP)是内核支持的用户线程,一个进程可以有一个或多个 LWP,每个 LWP 是跟内核线程一对一映射的,也就说 LWP 都是由一个内核线程支持。
LWP 只能由内核管理并像普通进程一样被调度,Linux 内核是支持 LWP 的。
在大多数系统中,LWP 与普通进程的区别也在于它只有一个最小的执行上下文和调度程序所需的统计信息。一般来说,一个进程代表程序的一个实例,而 LWP 代表程序的执行线程,因为一个执行线程不像进程那样需要多状态信息,所以 LWP 也不带这样的信息。
在 LWP 之上也是可以使用用户线程的,LWP 与用户线程的对应关系就有了三种:
1:1,一个 LWP 对应一个用户线程
N:1,一个 LWP 对应多个用户线程
N:N,多个 LWP 对应多个用户线程
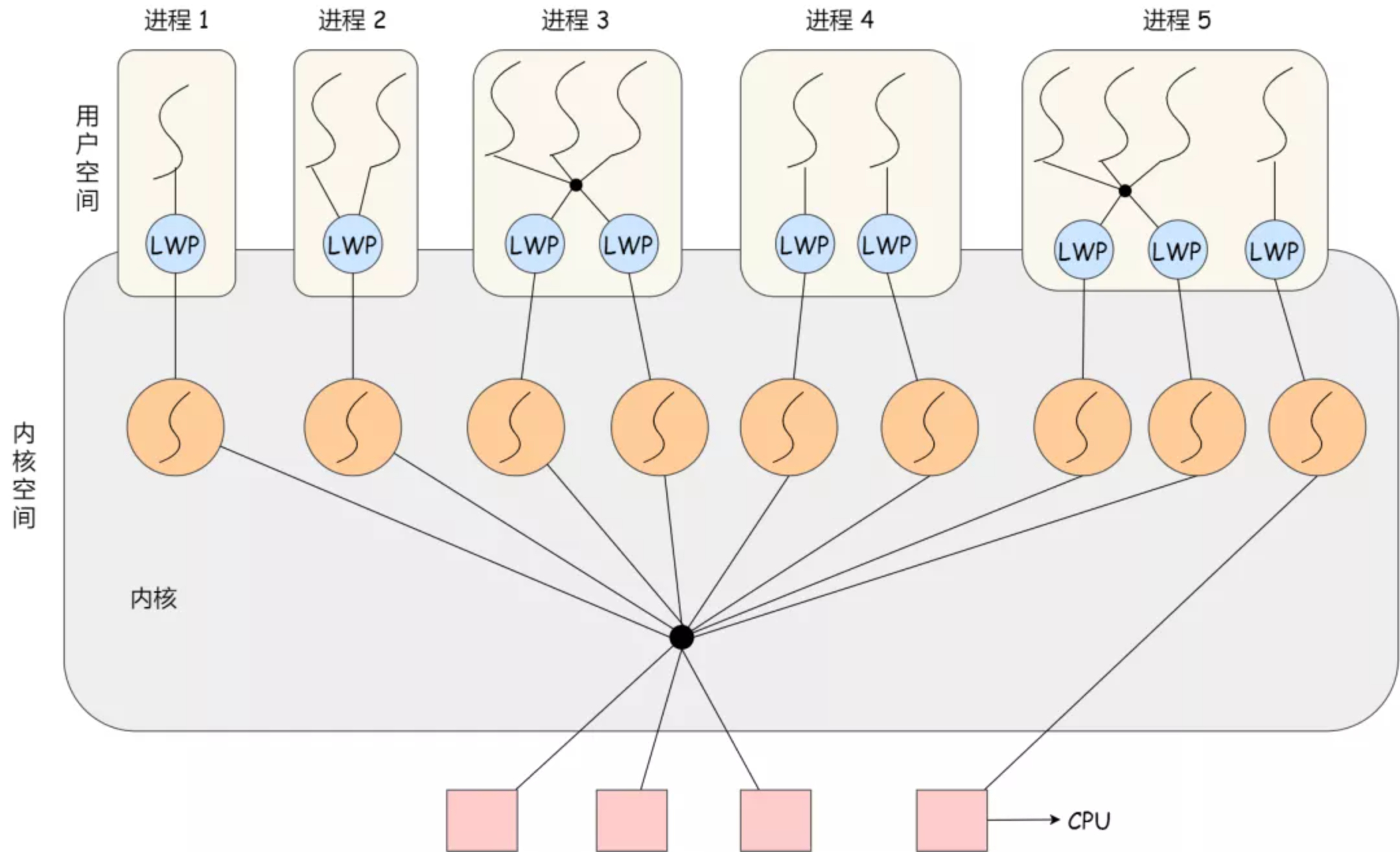
1:1 模式
一个线程对应一个 LWP 在对应一个内核线程
优点:实现并行,当一个 LWP 阻塞,不会影响其他 LWP
缺点:每一个用户线程,就产生一个内核线程,创建线程开销较大
N:1 模式
多个用户线程对应一个 LWP 在对应一个内核线程,线程管理是在用户空间完成的,此模式用的用户线程对操作系统不可见。
优点:用户线程要开几个都没问题,且上下文切换发生在用户空间,切换的效率较高
缺点:一个用户线程如果阻塞了,则这个歌进程都会阻塞,另外在多核 CPU 中,是没法充分利用 CPU 的
N:N 模式
该模型提供了两级控制,首先多个用户线程对应到多个 LWP,LWP 再一一对应到内核线程。
优点:综合了前两种优点,大部分的线程上下文发生在用户空间,且多个线程又可以充分利用多核 CPU 的资源
组合模式
如上图进程 5,此进程组合结合 1:1 模型和 N:N 模型。开发人员可以针对不同的应用特点调节内核线程的数目来达到物流并行性和逻辑并行性的最佳方案。
最后更新于